GIF
01
Extraction and Translation
Extract and translate from English, Korean, Japanese, Chinese, and other languages.
Extract and translate from English, Korean, Japanese, Chinese, and other languages.

Use local and cloud models to clean scans.
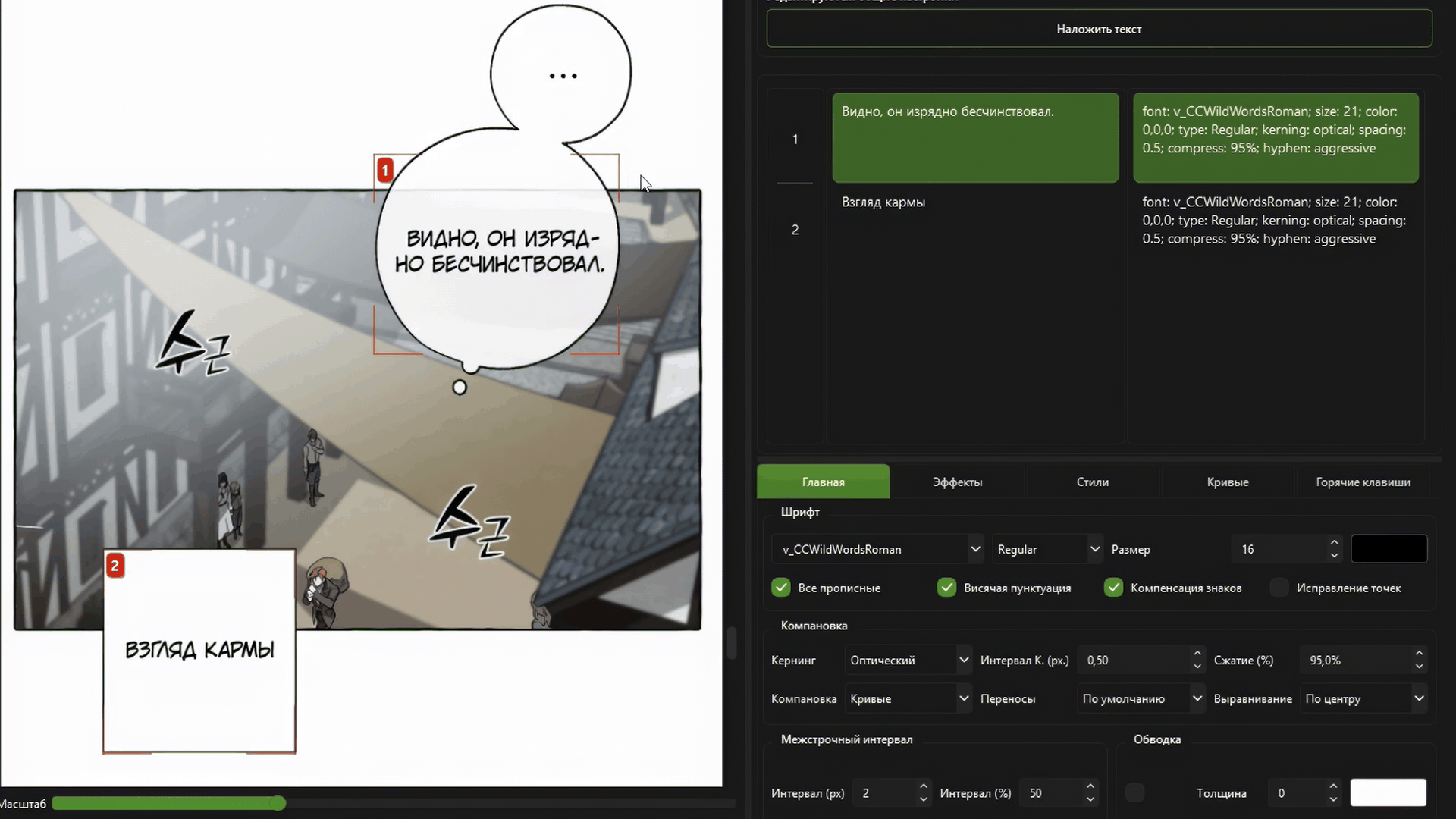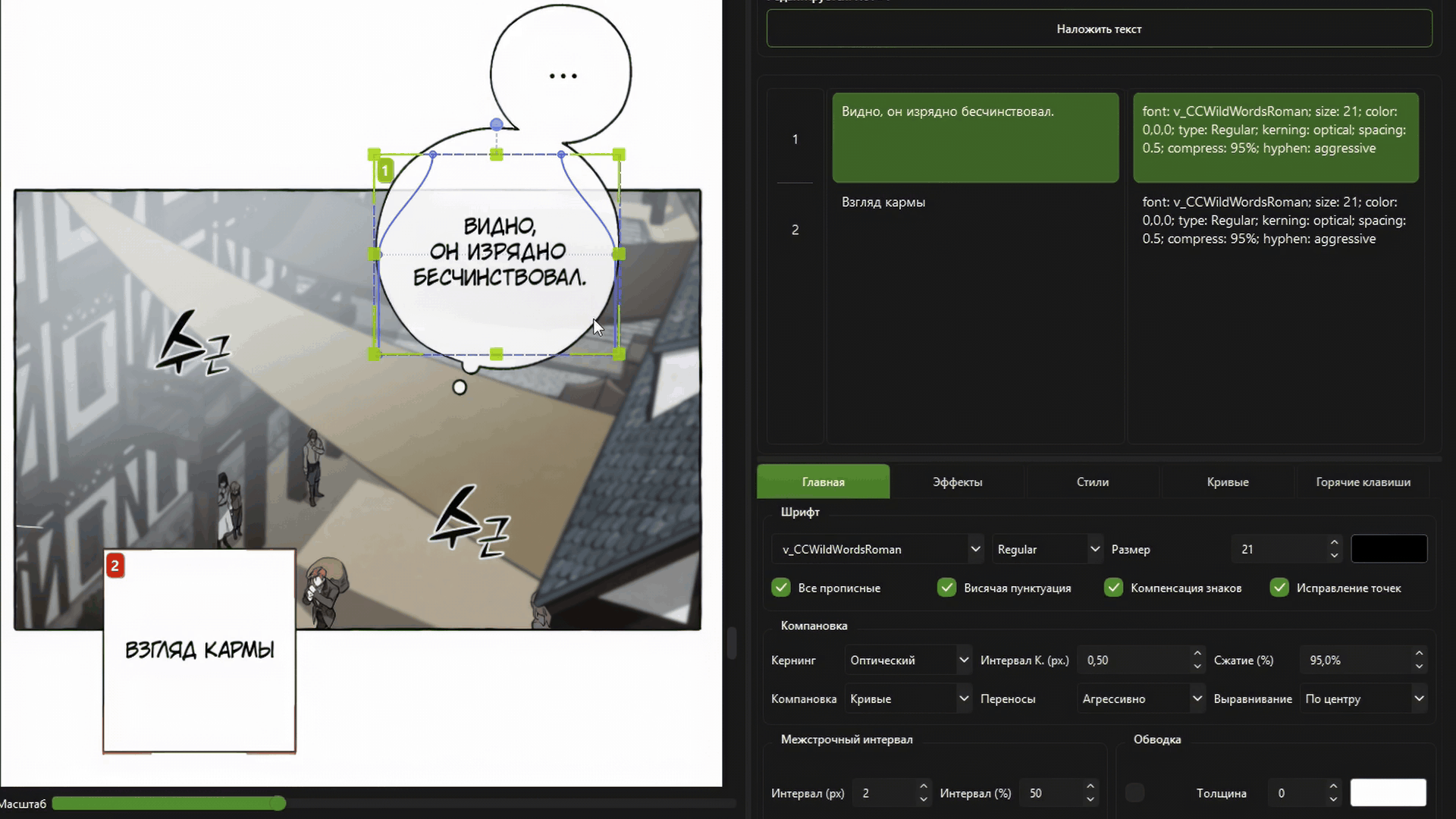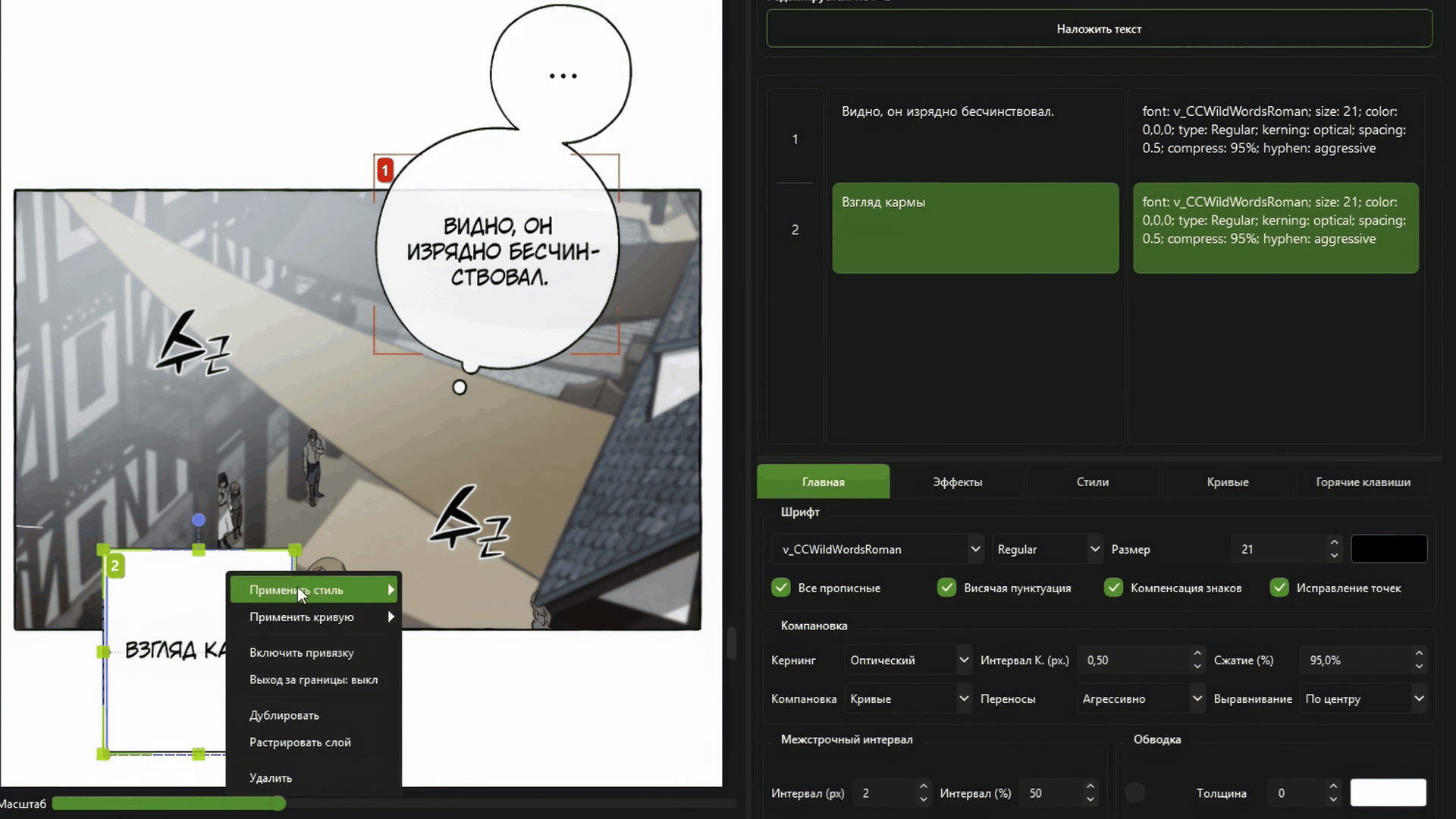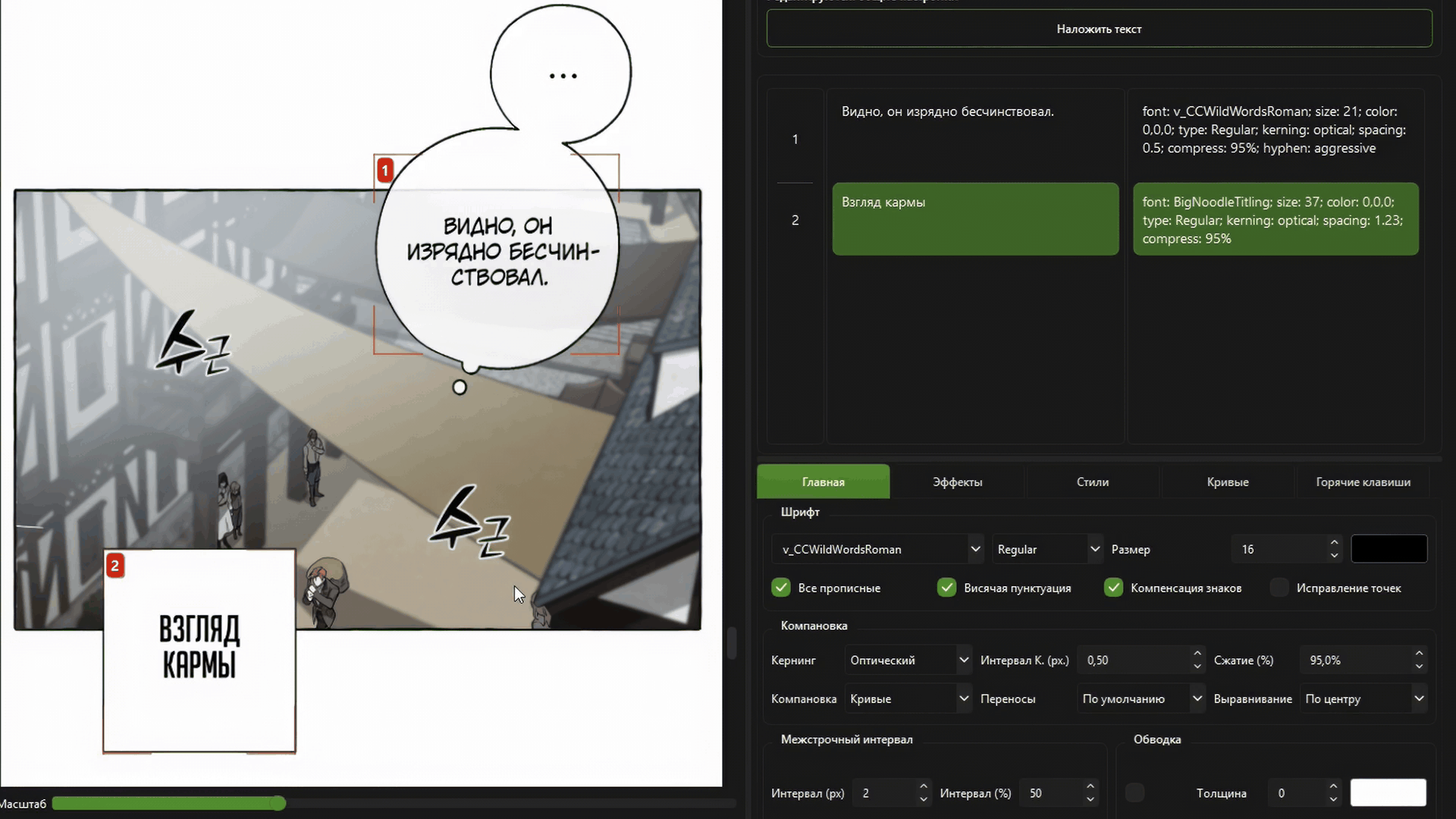
Full optical kerning and automatic text layout.
Минимальные требования: Windows 10 64-bit, 6 GB RAM, 12 GB свободного места на диске, процессор AMD FX-6300 или Intel Core i3-4130 (или новее).
Рекомендованные требования: Windows 10/11 64-bit, 12 GB RAM, 12 GB свободного места на диске, процессор Intel Core i5-8400 или AMD Ryzen 5 2600. Для ускорения обработки рекомендуется любая видеокарта с поддержкой CUDA (например, GTX 1050 Ti или выше).
ВНИМАНИЕ: Работа всего функционала не гарантируется на интегрированных видеокартах и дискретных видеокартах от AMD, а также видеокартах NVIDIA RTX 5000 серии!